How to index metadata for real life databases¶
From previous doc, we have indexed tables from a csv files. In real production cases, the table metadata is stored in data warehouses(e.g Hive, Postgres, Mysql, Snowflake, Bigquery etc.) which Amundsen has the extractors for metadata extraction.
In this tutorial, we will use a postgres db as an example to walk through how to index metadata for a postgres database. The doc won’t cover how to setup a postgres database.
-
In the example, we have a postgres table in localhost postgres named
films.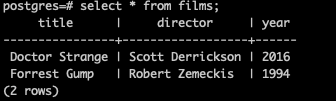
-
We leverage the postgres metadata extractor to extract the metadata information of the postgres database. We could call the metadata extractor in an adhoc python function as this example or from an Airflow DAG.
-
Once we run the script, we could search the
filmstable using Amundsen Search.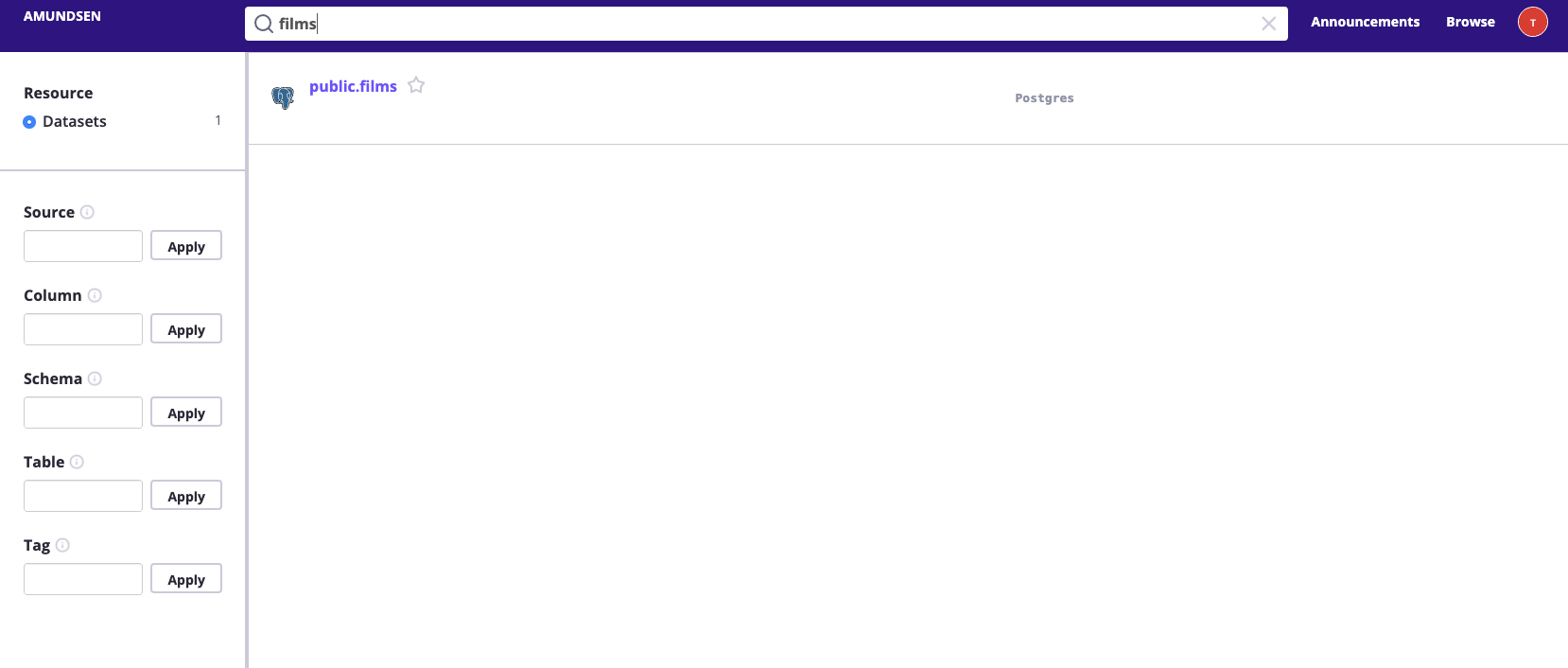
-
We could also find and view the
filmstable in the table detail page.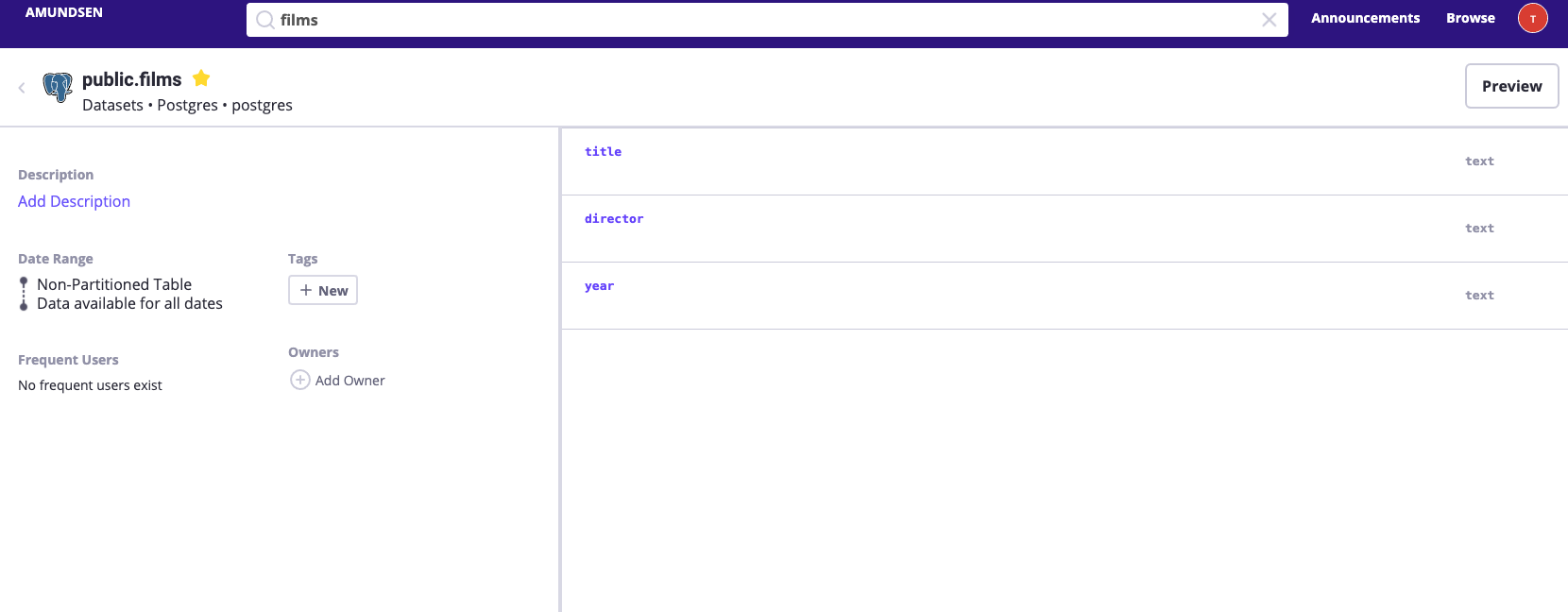
This tutorial uses postgres to serve as an example, but you could apply the same approach for your various data warehouses. If Amundsen doesn’t provide the extractor, you could build one based on the API and contribute the extractor back to us!