Installation¶
Bootstrap a default version of Amundsen using Docker¶
The following instructions are for setting up a version of Amundsen using Docker.
- Make sure you have at least 3GB of disk space available to Docker. Install
dockeranddocker-compose. - Clone this repo and its submodules by running:
$ git clone --recursive https://github.com/amundsen-io/amundsen.git - Enter the cloned directory and run the command below:
If it’s your first time, you may want to proactively go through troubleshooting steps, especially the first one related to heap memory for ElasticSearch and Docker engine memory allocation (leading to Docker error 137).
# For Neo4j Backend $ docker-compose -f docker-amundsen.yml up # For Atlas $ docker-compose -f docker-amundsen-atlas.yml up -
Ingest provided sample data into Neo4j by doing the following: (Please skip if you are using Atlas backend)
-
In a separate terminal window, change directory to databuilder.
sample_data_loaderpython script included inexamples/directory uses elasticsearch client, pyhocon and other libraries. Install the dependencies in a virtual env and run the script by following the commands below. See Windows Troubleshooting if you encounter an error onpython3 setup.py installregardingextas_requireon windows.$ python3 -m venv venv $ source venv/bin/activate $ pip3 install --upgrade pip $ pip3 install -r requirements.txt $ python3 setup.py install $ python3 example/scripts/sample_data_loader.py-
View UI at
http://localhost:5000and try to searchtest, it should return some result.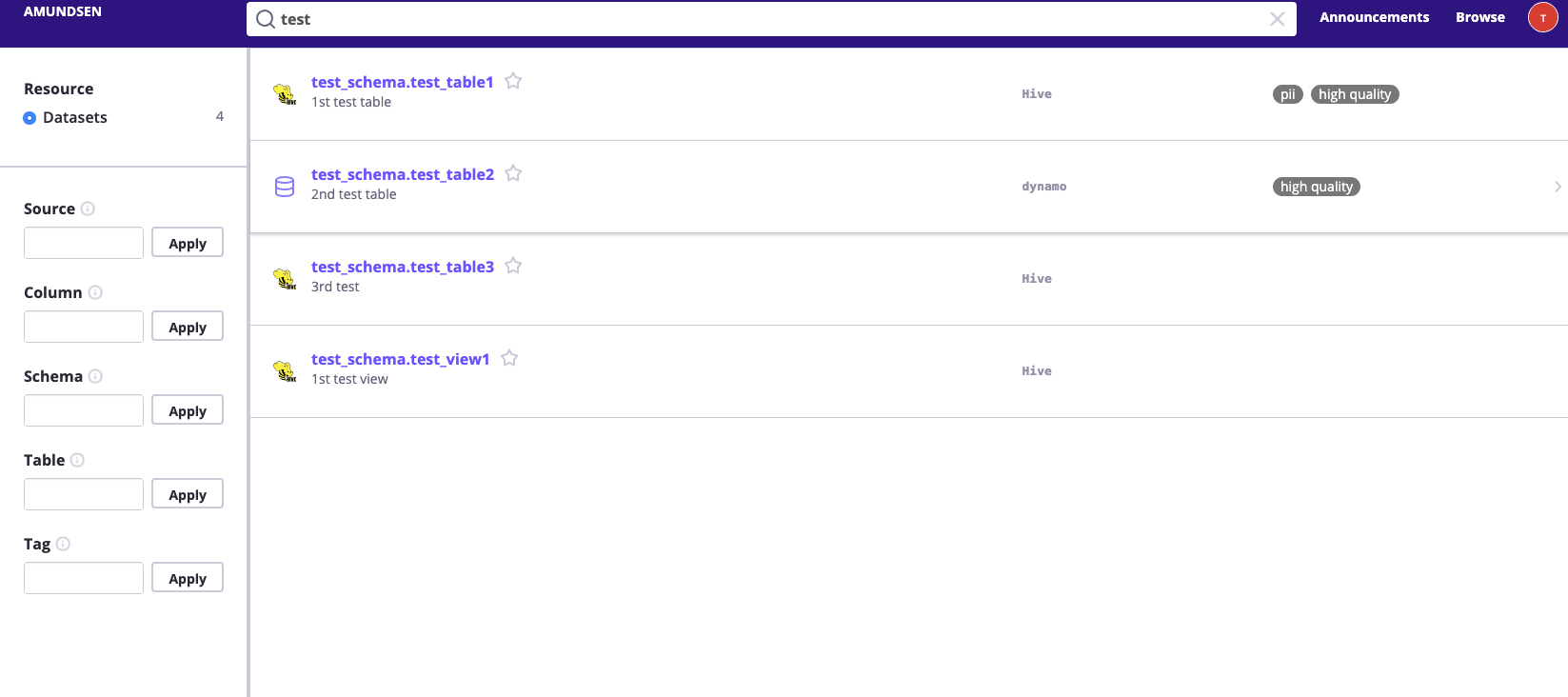
-
We could also perform an exact-match search for the table entity. For example: search
test_table1in table field and it’ll return the records that matched.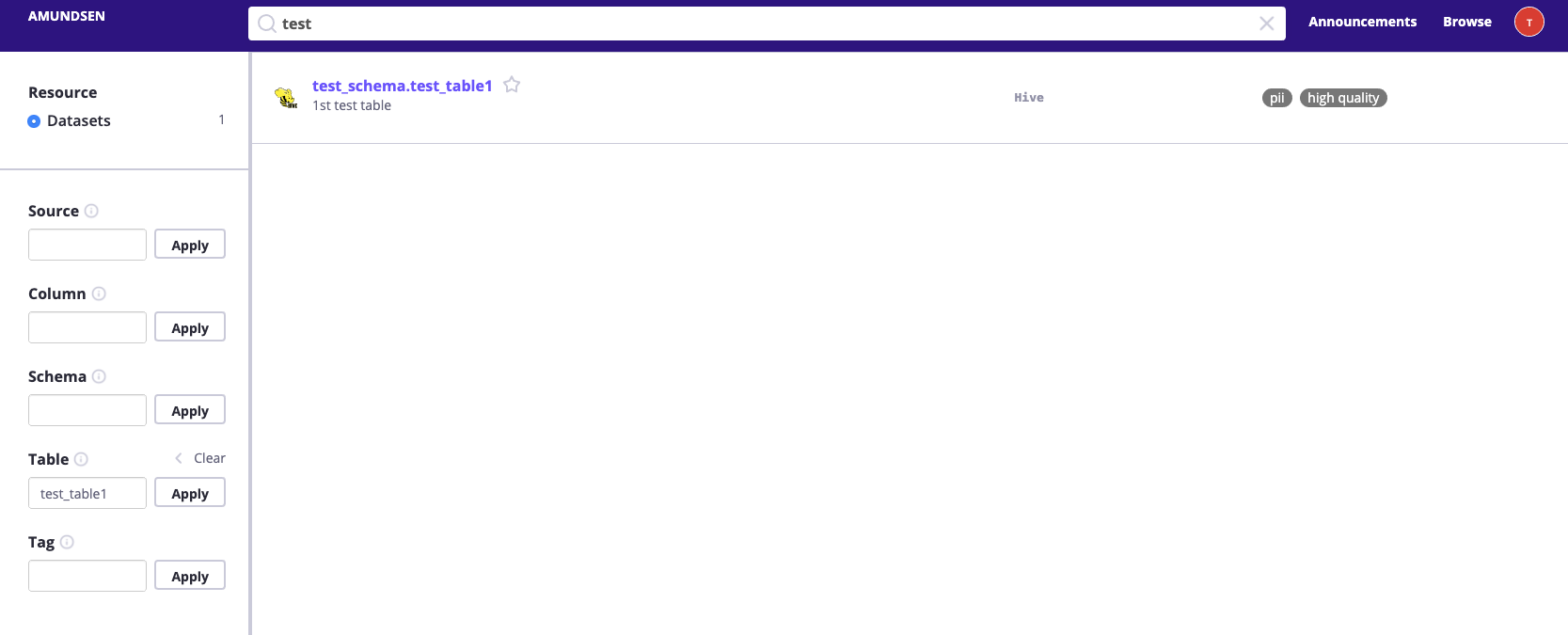
Atlas Note: Atlas takes some time to boot properly. So you may not be able to see the results immediately
after you run the docker-compose up command.
Atlas would be ready once you’ll have the following output in the docker output Amundsen Entity Definitions Created...
Verify your setup¶
- You can verify the dummy data has been ingested into Neo4j by by visiting
http://localhost:7474/browser/and runMATCH (n:Table) RETURN n LIMIT 25in the query box. You should see few tables.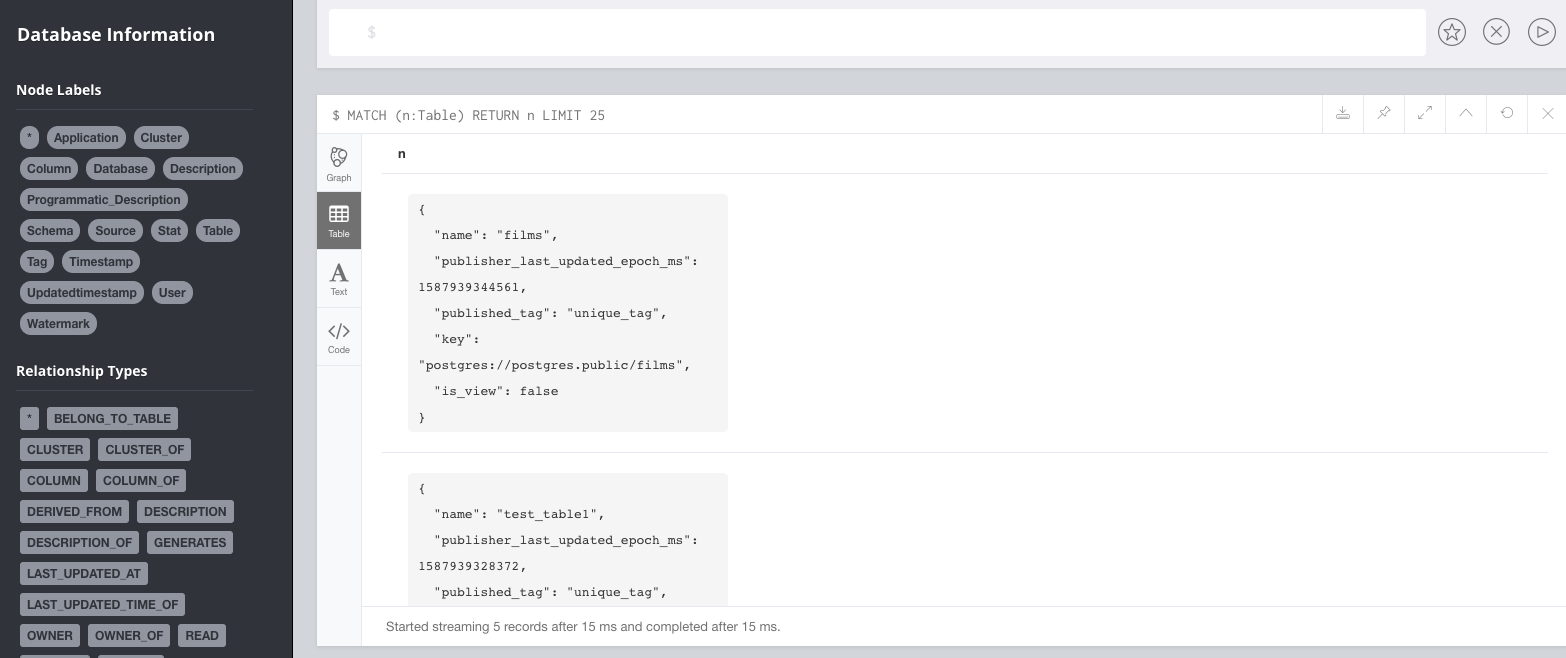
- You can verify the data has been loaded into the metadataservice by visiting:
http://localhost:5000/table_detail/gold/hive/test_schema/test_table1http://localhost:5000/table_detail/gold/dynamo/test_schema/test_table2
Troubleshooting¶
- If the docker container doesn’t have enough heap memory for Elastic Search,
es_amundsenwill fail duringdocker-compose. - docker-compose error:
es_amundsen | [1]: max virtual memory areas vm.max_map_count [65530] is too low, increase to at least [262144] -
Increase the heap memory detailed instructions here
- Edit
/etc/sysctl.conf - Make entry
vm.max_map_count=262144. Save and exit. - Reload settings
$ sysctl -p - Restart
docker-compose
- Edit
-
If
docker-amundsen-local.ymlstops because oforg.elasticsearch.bootstrap.StartupException: java.lang.IllegalStateException: Failed to create node environment, thenes_amundsencannot write to.local/elasticsearch. chown -R 1000:1000 .local/elasticsearch- Restart
docker-compose - If when running the sample data loader you recieve a connection error related to ElasticSearch or like this for Neo4j:
Traceback (most recent call last): File "/home/ubuntu/amundsen/amundsendatabuilder/venv/lib/python3.6/site-packages/neobolt/direct.py", line 831, in _connect s.connect(resolved_address) ConnectionRefusedError: [Errno 111] Connection refused -
If
elastic searchcontainer stops with an errormax file descriptors [4096] for elasticsearch process is too low, increase to at least [65535], then add the below code to the filedocker-amundsen-local.ymlin theelasticsearchdefinition.ulimits: nofile: soft: 65535 hard: 65535Then check if all 5 Amundsen related containers are running withdocker ps? Can you connect to the Neo4j UI at http://localhost:7474/browser/ and similarly the raw ES API at http://localhost:9200? Does Docker logs reveal any serious issues? -
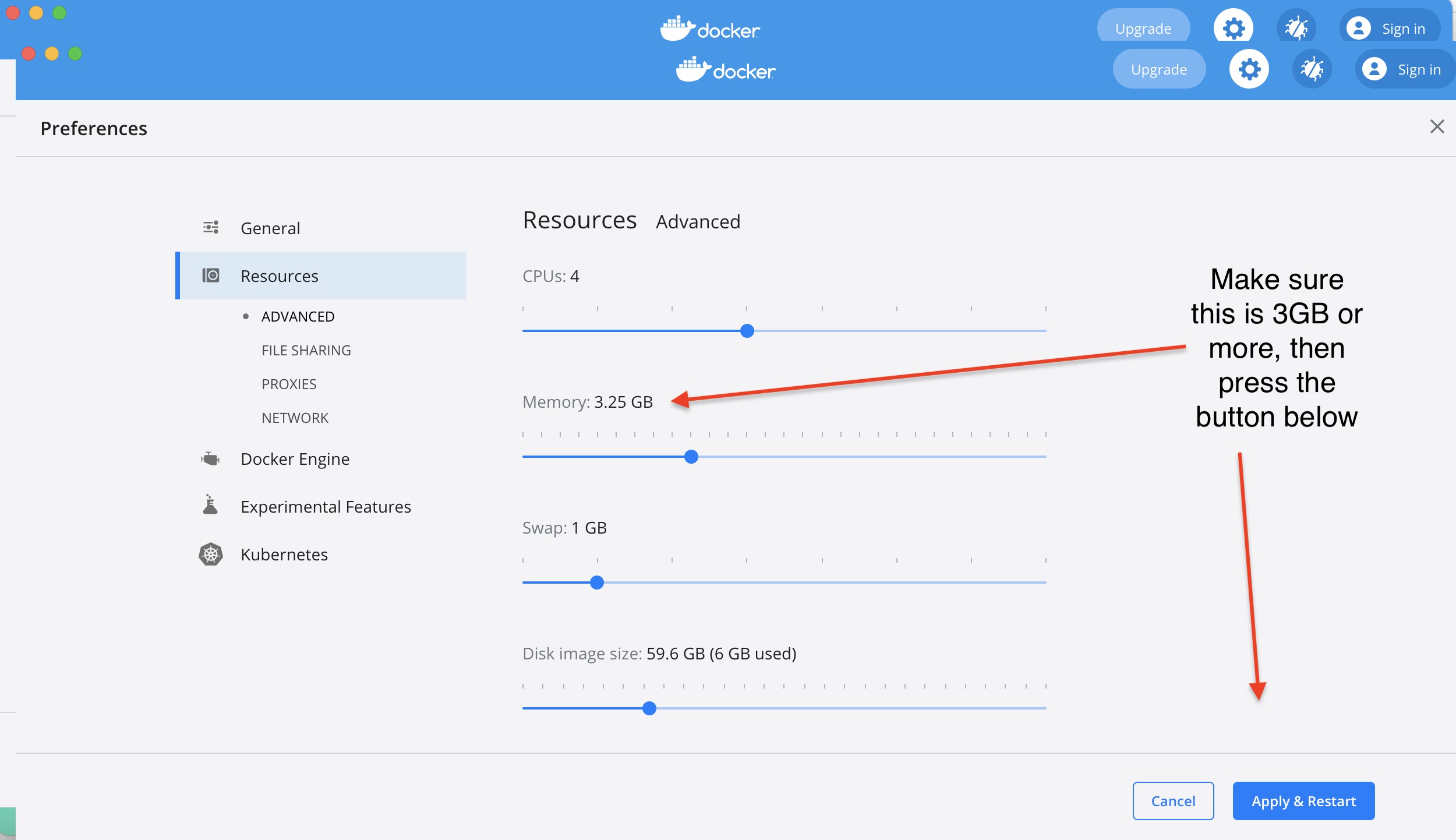
If ES container crashed with Docker error 137 on the first call from the website (http://localhost:5000/), this is because you are using the default Docker engine memory allocation of 2GB. The minimum needed for all the containers to run with the loaded sample data is 3GB. To do this go to your
Docker -> Preferences -> Resources -> Advancedand increase theMemory, then restart the Docker engine.